
I’ve been trying to transition from SD1.5 to SDXL for a while, but old prompting habits die hard.
Even more difficult was finding a model to produce the look I prefer. Most seem to love realism, 3D pixar style, anime, and super airbrushed.
If you have any tips for SDXL models, loras, prompting for this style, etc. please let me know!
parameters:
1girl, demon woman with bangs and ram horns and wings, holding bloody human heart, solo, sitting with knees up, (full body:0.6), looking at viewer, (dark fantasy theme:1.1) (glowing eyes:1.05), thick lines, flat shading
Negative prompt: low quality, deformed, embedding:negativeXL_D, embedding:unaestheticXL_Sky3.1,
Steps: 10, Sampler: dpmpp_3m_sde_simple, CFG scale: 1.0, Seed: 212036223314935, Size: 1024x1024, Model hash: 268a170aa6, Model: grogmixTURBO_v10
(and some inpainting/upscaling)

1girl, demon woman with bangs and ram horns and wings, holding bloody human heart, solo, sitting with knees up, (full body:0.6), looking at viewer, (dark fantasy theme:1.1) (glowing eyes:1.05), thick lines, flat shading <lora:color_vector:1> <lora:The_Simplest:0.5> <lora:GNXL-Line Art:0.6> Negative prompt: low quality, deformed, bad anatomy, (extra feet:2), extra ears, extra tails, signature, artist name Steps: 10, Sampler: DPM++ 3M SDE, CFG scale: 1, Seed: 212036223314935, Size: 1024x1024, Model hash: 7f63ddc0d8, Model: zavychromaxl_v50, VAE hash: 235745af8d, VAE: fixFP16ErrorsSDXLLowerMemoryUse_v10.safetensors, Denoising strength: 0.3, Hypertile VAE: True, Hires upscale: 1.5, Hires upscaler: 4x-AnimeSharp, Lora hashes: "color_vector: 244e3944f033, The_Simplest: a482d04bf144, GNXL-Line Art: 13ce5f42806b", Postprocess upscale by: 2, Postprocess upscaler: 4x-AnimeSharp, Version: v1.7.0
1girl, demon woman with bangs and ram horns and wings, holding bloody human heart, solo, sitting with knees up, (full body:0.6), looking at viewer, (dark fantasy theme:1.1) (glowing eyes:1.05), thick lines, flat shading <lora:The_Simplest:0.5> Negative prompt: low quality, deformed, (bad anatomy:2), (extra limbs:2), (extra feet:2), tits, fire, extra ears, extra tails, signature, artist name Steps: 10, Sampler: DPM++ 3M SDE, CFG scale: 1, Seed: 212036223314935, Size: 1024x1024, Model hash: 7f63ddc0d8, Model: zavychromaxl_v50, VAE hash: 235745af8d, VAE: fixFP16ErrorsSDXLLowerMemoryUse_v10.safetensors, Denoising strength: 0.3, Hypertile VAE: True, Hires upscale: 1.5, Hires upscaler: 4x-AnimeSharp, Lora hashes: "The_Simplest: a482d04bf144", Postprocess upscale by: 2, Postprocess upscaler: 4x-AnimeSharp, Version: v1.7.0I don’t know if it’s what you want, but: using the same prompt terms, and grabbing my favorite in a batch of 20:

1girl, demon woman with bangs and ram horns and wings, holding bloody human heart, solo, sitting with knees up, (full body:0.6), looking at viewer, (dark fantasy theme:1.1) (glowing eyes:1.05), thick lines, flat shading
Negative prompt: low quality, deformed, embedding:negativeXL_D, embedding:unaestheticXL_Sky3.1,
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 13, Size: 1024x1024, Model hash: ebf42d1fae, Model: realmixXL_v15, Token merging ratio: 0.5, Version: v1.7.0-270-g04a005f0
I’m guessing that, relative to that, you’re looking for something that looks more like a painting?
Looking at civitai, grogmixTURBO, which you’re using, seems to typically produce more anime-looking images than you’re generating.
That’s actually a good example of the overly airbrushed look I was trying to describe. So many models have output like that.
As for GrogMixTURBO, I found the keywords “thick lines, flat shading” from one of the creator’s replies to a comment on the model page, and these magically gave me what I wanted with that model.
Have you tried finding an artist who has similar work and trying “by <artistname>”?
I did that with RealCartoon-XL, and soooometimes it gave good results for the style, but inconsistent. I guess I just got too used to SD1.5 models specializing in a certain aesthetic.
Gotcha. Hmm.
Have you tried browsing images under XL models on civitai for anything that is similar to the aesthetic you like, and then swiping their prompt terms?
If you’re gonna use the base model, you can try Clip Interrogator on your image to find terms that will generate similar images, but that didn’t do much for me. I don’t think the base model is trained much on succubi.
Definitely! That’s how I was able to find the ones I listed in another comment. Without this, I’d be doomed 😆
If you can avoid the turbo/lightning models, they’re not as good as regular XL.
Likewise with XL the less negative prompts the better, I usually operate on none or only ‘text,watermark’
As for style, LORA or prompting an artists name is your best bet.
If you’re after anime/cartoon, Ponydiffuser is the best. It operates on booru tags, so it can’t imagine much outside of that range but the flipside is it can create basically anything within those confines. Pony also has an extremely wide range of artist/style LORA to recreate any sort of look you’re after.
For realism you’ve got a few options of models, none are stand-out better than the other top rated ones.
I usually go with the full models, but for some reason GrogMix only has turbo and can nail the look I’m after.
I keep seeing positive sentiments about Pony everywhere I look, so I’ll keep trying with that one. Right now, I’m having trouble with any character that isn’t very close. Anything slight back from super closeup portrait loses a ton of detail, even with hires fix and multiple rounds of upscaling.
What front end are you using? I can try to whip up something and share a json if you’re using comfyui.
A comfyui json would be much appreciated!
One last thing, can you share an example of the sort of art style you’re after? All I know is not realism, 3D pixar style, anime, and super airbrushed.
This account on civitai has many many good examples, but all SD1.5 https://civitai.com/user/TxcTrtl/images?sort=Most+Reactions
Sure! The main image of this post is one example.
And here are a few more (all from SD1.5 models):spoiler




Need a bit more work on the outlines aspect and will probably want to prompt for more muted/natural colours, but this is as close as I can get for 2am.


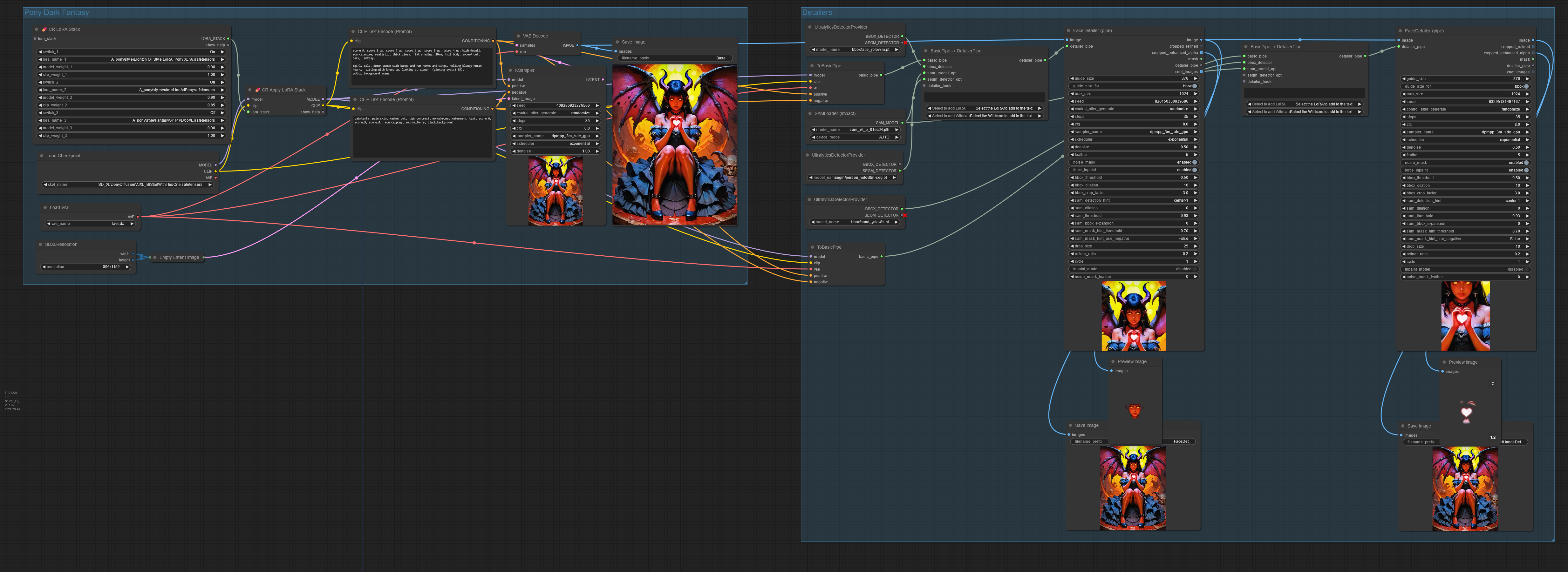
The second group is optional, but it’ll more often than not fix up faces and hand errors.
Thanks a lot for making this! I’m starting to have some luck with the Pony model finally. It’s crazy how many resources that model has already.
Looks more like a heart harvester
Ones I’ve found so far are:
- GrogMix TURBO
- _CHEYENNE_
- RealCartoon-XL (sometimes?)
- PixelPaint
- PixelWaveTurbo
I’ve seen good images using Pony XL, but my attempts with it have so far produced messy slop so I’m not sure what I’m doing wrong there.
Check out the important information section on Pony Diffusion V6 XL’s page. It says: “Make sure you load this model with clip skip 2 (or -2 in some software), otherwise you will be getting low quality blobs.”. Find some images you like and work off of their prompts to learn to make your own,
Thanks for the reply, but yeah, I’ve definitely tried that. In ComfyUI for this model, setting it to -2 doesn’t actually do anything compared to no node for that at all. Setting it to -1 of course ruins it though.
It seems really temperamental with the styles. It seems to vastly change just by changing a few words that aren’t related to style at all.
This is the best I’ve gotten with it after hours if fiddling. Most of the image is good, but the face and hands never are.

Try using some LoRA. You have to use LoRA trained on Pony Diffusion, since the training process moved it far away enough from regular SDXL that Controlnets aren’t even compatible with it,
Yeah it seems like loras are necessary. For that image I used the concept art twilight lora.

{kind=link}