

Not specified for this research but… if you rely on LLM to write code that is security-sensitive, I don’t expect you to write secured code without LLM anyway
I’m doing my part by writing really shitty foss projects for AI to steal and train on.
It seems to me that if one can adequately explain the function of their pseudocode in adequate detail for an LLM to turn it into a functional and reliable program, then the hardest part of writing the code was already done without the LLM.
No worries, the properly implemented CI/CD pipelines will catch the bad code!
I had a student came into office hours asking why their program got a bad grade. I looked and it didn’t actually do anything related to the assignment.
Upon further query, they objected saying that the CI pipeline built it just fine.
So …yeah… You can write a program that builds and runs, but doesn’t do the required tasks, which makes it wrong. This was not a concept they’d figured out yet.
Shouldn’t the pipeline have failed unless the functional tests passed?
Until you find out those were also built by a junior using an llm to help 🙃
I really don’t get how its different than a search engine. Granted its surprising how often I have to give up in disgust and just go back to normal search but pretty often they can find more relevant stuff faster
I really don’t get how its different than a search engine
Neither did this guy.
The difference is that LLM output is (in the formal sense) bullshit.
so is search. I mean I would not click the first link from a search and then copy and paste code from the site into my project no questions asked. similarly you can look over what the ai comes up with and see if it makes sense. same you would do with some dudes blog. you can also check the references it gives or ask it to expand on some part. hey what does the function X do. I really don’t see it as being worse than search.
not that you should be copy pasting any significanct amount of code, but at least when you do you’re required to understand it enough to fit it into your program. LLMs just straight up camouflage the shit code by putting something that already fits and has no squiggly red lines beneath. Many people probably don’t bother reading it at that point.
yeah I mean by that standard anything a person like that uses is going to be an issue. They can be useful but im worried about the power they use although I wonder how much power that is realtive to be searching different blogs for 10 or 20 minutes.
For a point of comparison, a ChatGPT request uses 2.9 watt-hours (and rising) to a google searches 0.3 (which per your example would only be run once assuming you’re checking different blogs from the same list of results.)
generally I end up checking some results and often changing the search with new keywords but all the same I generally am doing follow up questions similarly. Im betting to any energy the ai uses to check web destinations is likely not included which would be the same as I going to a destination. maybe less if its more of a crawl or api. Any way you slice it its going to be more I think.
People like to gatekeep easy access to knowledge for some reason.
2023? Like last year? Like when LLMs were just a curiosity more than anything useful?
They should be doing these studies continuously…
Edit: Oh no, I forgot Lemmy hates LLMs. Oh well, can’t blame you guys, hate is the basic manifestation towards what scares you, and it’s revealing.
I’m sure they will, here’s year one.
Unlike this year when LLMs are more of a huge scam.
We’re entering the ‘blockchain for every need’ stage. Expect massive money to flow into scams, poor ideas, and outright dangerous uses for a few years .
Before Blockchain we had ‘the web’ itself in the dot com era. Before that? I saw it in basic computing as a solution to everything.
Curious why your perspective is they’re are more of a scam when by all metrics they’ve only improved in accuracy?
Source?
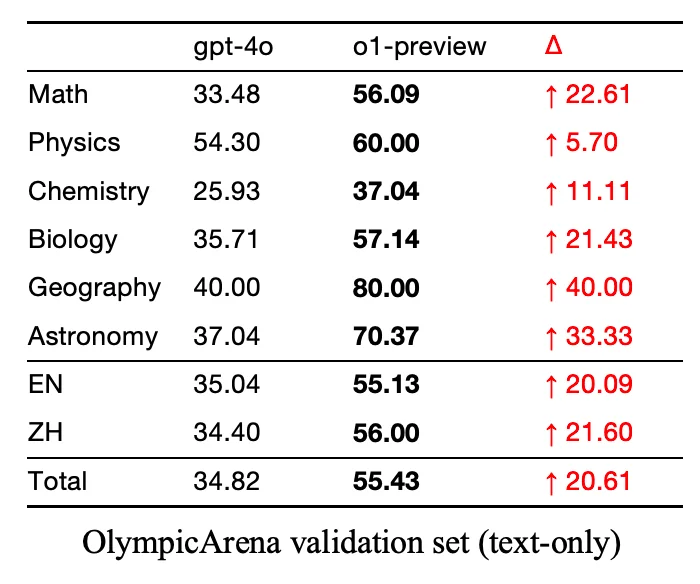
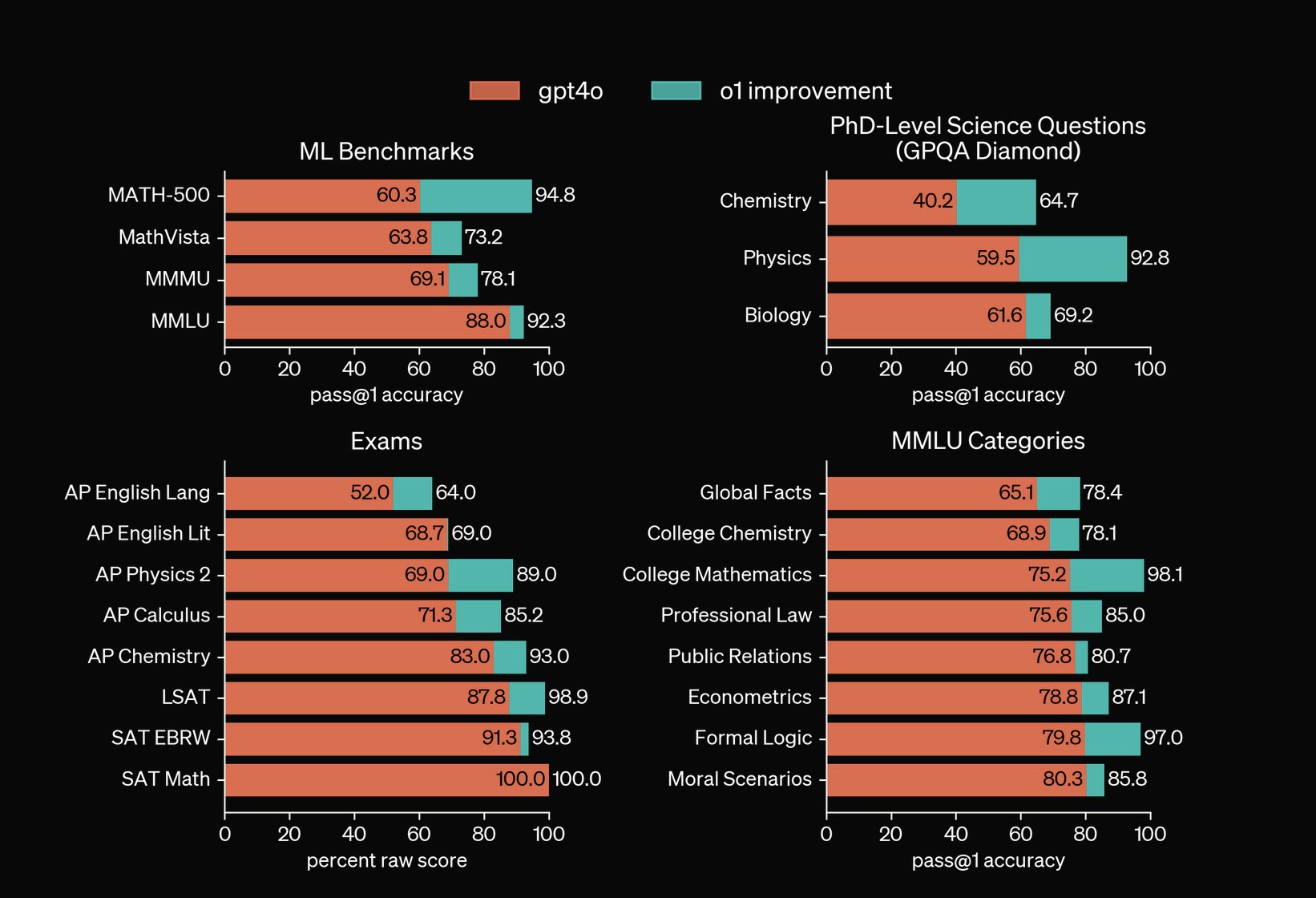
Compare the GPT increase from their V2 GPT4o model to their reasoning o1 preview model. The jumps from last years GPT 3.5 -> GPT 4 were also quite large. Secondly if you want to take OpenAI’s own research into account that’s in the second image.
if you want to take OpenAI’s own research into account
No thank you.
OlympicArena validation set (text-only)
“Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy (28.67% for mathematics and 29.71% for physics)”
- The OlympicArena analysis that you cited.
The jump from GPT-4o -> o1 (preview not full release) was a 20% cumulative knowledge jump. If that’s not an improvement in accuracy I’m not sure what is.
One of the first things they teach you in Experimental Physics is that you can’t derive a curve from just 2 data points.
You can just as easilly fit an exponential growth curve to 2 points like that one 20% above the other, as you can a a sinusoidal curve, a linear one, an inverse square curve (that actually grows to a peak and then eventually goes down again) and any of the many curves were growth has ever diminishing returns and can’t go beyond a certain point (literally “with a limit”)
I think the point that many are making is that LLM growth in precision is the latter kind of curve: growing but ever slower and tending to a limit which is much less than 100%. It might even be like more like the inverse square one (in that it might actually go down) if the output of LLM models ends up poluting the training sets of the models, which is a real risk.
You showing that there was some growth between two versions of GPT (so, 2 data points, a before and an after) doesn’t disprove this hypotesis. I doesn’t prove it either: as I said, 2 data points aren’t enough to derive a curve.
If you do look at the past growth of precision for LLMs, whilst improvement is still happening, the rate of improvement has been going down, which does support the idea that there is a limit to how good they can get.
One or two models have increased in accuracy. Meanwhile all the grifters have caught on and there’s 1000x more AI companies out there that are just reselling ChatGPT with some new paint.
That’s definitely valid, but just because a tool is used for scam doesn’t inherently mean it’s a scam. I don’t call the cellphone a scam because most my calls are.
They do. Reality is not going to change though. You can enable a handicapped developer to code with LLMs, but you can’t win a foot race by using a wheelchair.
I’m just waiting for someone to lecture me how the speed record in wheelchair sprint beats feet’s ass…
Hmm. To me 2023 was the breakthrough year for them. Now we are already getting used to their flaws.
Hmmm, it’s almost like the study was testing peoples perception of the usefulness of AI vs the actual usefulness and results that came out.
While I agree “they should be doing these studies continuously” point of view, I think the bigger red flag here is that with the advancements of AI, a study published in 2023 (meaning the experiment was done much earlier) is deeply irrelevant today in late 2024. It feels misleading and disingenuous to be sharing this today.
No. I would suggest you actually read the study.
The problem that the study reveals is that people who use AI-generated code as a rule don’t understand it and aren’t capable of debugging it. As a result, bigger LLMs will not change that.
I did in fact read the paper before my reply. I’d recommend considering the participants pool — this is a very common problem in most academic research, but is very relevant given the argument you’re claiming — with vast majority of the participants being students (over 60% if memory serves; I’m on mobile currently and can’t go back to read easily) and most of which being undergraduate students with very limited exposure to actual dev work. They are then prompted to, quite literally as the first question, produce code for asymmetrical encryption and deception.
Seasoned developers know not to implement their own encryption because it is a very challenging space; this is similar to polling undergraduate students to conduct brain surgery and expect them to know what to look for.
Its the inherent disconnect between “News” and “Science”.
Science requires rigorous study and incremental advancement. A 2023 article based on 2022 data is inherently understood to be… 2022 data (note: I did not actually check but that is the timeline I assume. It is in the study).
But news and social media just want headlines that get people angry and reinforce whatever nonsense people want to Believe.
It is similar to explaining basic concepts. Been a minute since the last time I was properly briefed, but think stuff like “Do NOT say ‘theory’ of evolution. Instead, talk about how evolution is the only accepted justification based on evidence and research”
Completely agree with you on the news vs science aspect. At the same time, it is worth considering that not all science researches are evergreen… I know this all too well; as a UX researcher in the late 2000s / early 2010s studying mobile UX/UI, most of the stuff our lab has done was basically irrelevant the year after they were published. Yet, the lab preserved and continues to conduct studies and add incremental knowledge to the field. At the pace generative AI/LLMs are progressing, studies against commercially available models in 2023 is largely irrelevant in the space we are in, and while updated studies are still important, I feel older articles doesn’t shine an appropriate light on the subject in this context.
A lot of words to say that despite the linked article being a scientific research, since the article is dropped here without context nor any leading discussion, it leans more towards the news spectrum, and gives off the impression that OP just want to leverage the headline to strike emotion and reinforce peoples’ believes on outdated information.
It isn’t about being “evergreen”. It is about having historical evidence.
Because maybe someone will do a study in 2030 and want to be able to compare to your UX research in the 2000s. If you wrote your paper properly they can reproduce your experiments (to the degree reasonable) and actually demonstrate progress.



