Creating a web scraper vs actually maintaining one that is effective and works is two different things. It’s very easy to fight web scraping if you know what you are doing.
You are right. You would need a team of skilled scrapers and network engineers though would know how to get around rate limiters with some kind of external load balancer or something along those lines.
Rate limiters work on IP source. This is easily bypassed with a rotating proxy. There are even SaaS that offer this. The trick is to not use large subnets that can be easily blocked. You have to use a lot of random /32 IPs to be effective.
Could they be doing that already because of the still open API of Reddit and that will soon change? I just feel like it’s easier for them currently and it will be tougher once the API changes are implemented.
No. Search engines fetch pages using plain old HTTP GET requests, same as how browsers fetch pages. There is some difficulty in parsing the HTML and extracting meaningful content, but it’s too late: the HTML is already stored on Google/Microsoft servers, ready for extraction, and there’s nothing Reddit can do to stop them.
Reddit can make future content harder to extract, but not without also making it invisible to search engines, which would cause Reddit to disappear from Google Search and Bing.
That’s why I say trying to charge money for AI training data is a fool’s errand. These facts make it impossible. That doesn’t mean Spez won’t try, but it does mean he won’t succeed.


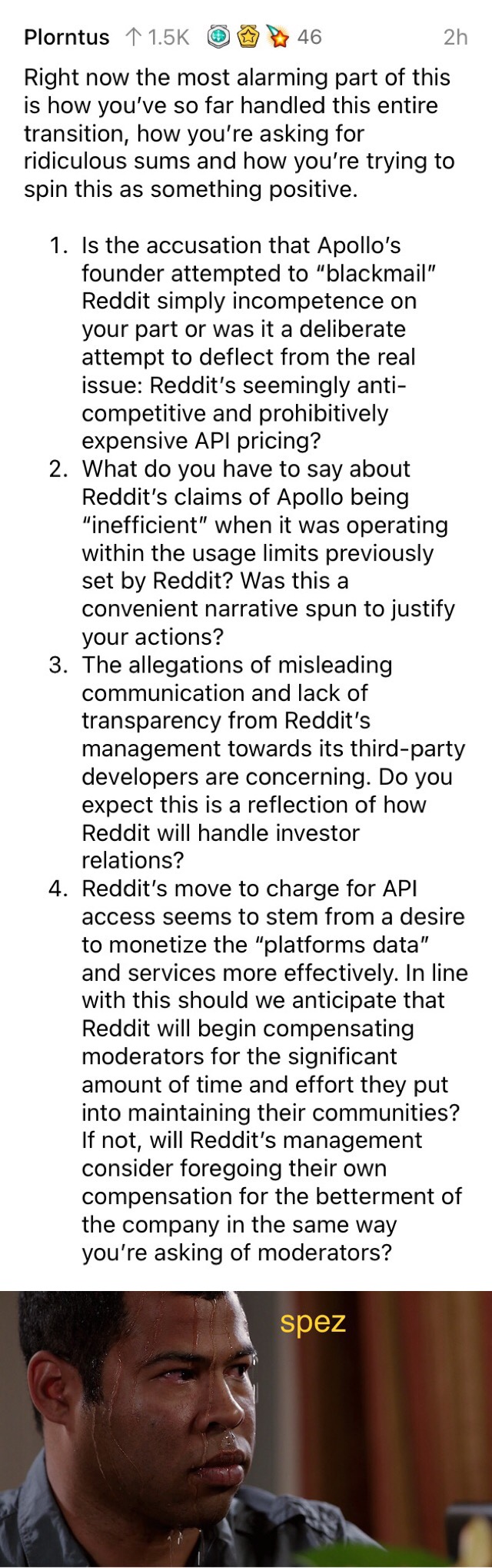{kind=link}
Creating a web scraper vs actually maintaining one that is effective and works is two different things. It’s very easy to fight web scraping if you know what you are doing.
Right, but these are big companies with lots of talented programmers on hand. If anyone can overcome such an obstacle, it’s them.
Also, Google and Microsoft already have a search index full of Reddit content to scrape.
You are right. You would need a team of skilled scrapers and network engineers though would know how to get around rate limiters with some kind of external load balancer or something along those lines.
Rate limiters work on IP source. This is easily bypassed with a rotating proxy. There are even SaaS that offer this. The trick is to not use large subnets that can be easily blocked. You have to use a lot of random /32 IPs to be effective.
That problem is already solved. Google and Microsoft are already fetching every single page on Reddit for search engine indexing.
Could they be doing that already because of the still open API of Reddit and that will soon change? I just feel like it’s easier for them currently and it will be tougher once the API changes are implemented.
No. Search engines fetch pages using plain old HTTP
GETrequests, same as how browsers fetch pages. There is some difficulty in parsing the HTML and extracting meaningful content, but it’s too late: the HTML is already stored on Google/Microsoft servers, ready for extraction, and there’s nothing Reddit can do to stop them.Reddit can make future content harder to extract, but not without also making it invisible to search engines, which would cause Reddit to disappear from Google Search and Bing.
That’s why I say trying to charge money for AI training data is a fool’s errand. These facts make it impossible. That doesn’t mean Spez won’t try, but it does mean he won’t succeed.